TL;DR
- Tier nie opisuje pojedynczego UPS-a, agregatu albo rozdzielnicy. Opisuje fizyczną topologię całej infrastruktury: zasilania, chłodzenia, dystrybucji, tras kablowych, automatyki i możliwości utrzymania obiektu w ruchu.
- Uptime Institute i TIA-942 używają czterostopniowej klasyfikacji, ale nie należy traktować ich jako identycznych systemów oceny. W tym artykule przyjmuję perspektywę topologii według Uptime Institute. [1][2]
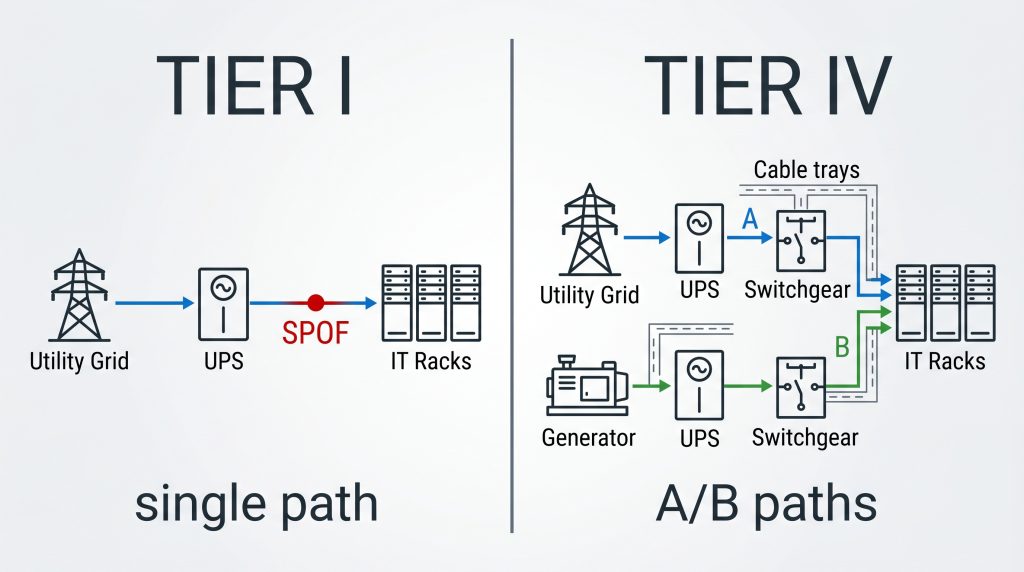
- Tier I to pojedyncza ścieżka i brak redundancji. Tier II dodaje redundantne komponenty, ale dalej opiera się na jednej ścieżce. Tier III umożliwia planowany serwis bez wyłączenia IT. Tier IV wymaga odporności na pojedynczą awarię.
- Historycznie z poziomami Tier często łączy się orientacyjne wartości dostępności: 99,671%, 99,741%, 99,982% i 99,995%. Nie są one jednak gwarantowanym wynikiem certyfikacji Uptime Institute.
- Najczęstszy błąd projektowy: patrzenie na liczbę urządzeń zamiast na ostatni wspólny punkt awarii. Dwa UPS-y nie tworzą Tier III, jeśli za nimi zostaje jedna szyna, jeden bypass albo jedna trasa kablowa.
- Jeżeli obiekt ma elementy klasy Tier IV, ale mechanizm utrzymania zasilania wymaga postoju jak w Tier II, dostępność całego obiektu będzie bliższa Tier II niż Tier IV.
W zasilaniu obiektów krytycznych łatwo pomylić dwie rzeczy: liczbę urządzeń i odporność całej architektury.
Dwa UPS-y nie oznaczają automatycznie Tier III. Dwa tory A/B nie oznaczają automatycznie Tier IV. Redundancja narysowana na schemacie nie oznacza jeszcze odporności podczas awarii albo serwisu.
Klasy Tier powstały po to, żeby uporządkować ocenę obiektów data center pod kątem fizycznej topologii infrastruktury. Taki podział pomaga ocenić dostępność obiektu, skalę inwestycji, koszty budowy, koszty utrzymania i wpływ ewentualnej przerwy na systemy teleinformatyczne. [1]
Dla elektryka najważniejsze pytanie nie brzmi: „ile mamy UPS-ów?”. Lepsze pytanie brzmi: gdzie jest ostatni wspólny punkt awarii?
Dwa standardy, jedna nazwa Tier
W praktyce spotyka się dwa podziały na klasy Tier.
Pierwszy wprowadził Uptime Institute pod koniec lat 90. XX wieku. Ten podział skupia się na topologii centrów przetwarzania danych, dostępności infrastruktury i czasie niedostępności wynikającym z awarii lub prac utrzymaniowych. [1]
Drugi podział został wprowadzony przez Telecommunications Industry Association w standardzie TIA-942 w 2005 roku. TIA-942 opisuje szersze wymagania dla obiektów data center: infrastrukturę, architekturę telekomunikacyjną, okablowanie, bezpieczeństwo, kontrolę dostępu, dystrybucję usług i organizację pomieszczeń. [2]
Oba podejścia używają czterostopniowej logiki oceny, ale różnią się sposobem klasyfikacji. W TIA-942-B oficjalnie stosuje się oznaczenia Rated-1 do Rated-4, choć w rozmowach branżowych nadal często spotyka się skrótowe porównanie do Tier I-IV.
W standardzie TIA-942 osiągnięcie danego poziomu wymaga spełnienia wymagań przypisanych do tej klasy. Jeżeli jeden z obszarów nie spełnia wymagań, obiekt może nie zostać zakwalifikowany do deklarowanego poziomu.
W podejściu Uptime Institute większy nacisk położony jest na topologię i osiągnięcie wymaganego zachowania infrastruktury. Liczy się to, czy układ faktycznie zapewnia wymaganą dostępność, możliwość utrzymania oraz odporność na uszkodzenia.
W dalszej części opisuję klasy Tier z perspektywy Uptime Institute, bo ta perspektywa jest najbardziej użyteczna przy analizie układów zasilania gwarantowanego.
Czego Tier nie opisuje
Tier nie jest etykietą urządzenia.
UPS nie ma klasy Tier. Agregat nie ma klasy Tier. Rozdzielnica sama w sobie też jej nie ma. Klasę można przypisać topologii obiektu, a nie pojedynczemu komponentowi.
To ma praktyczne konsekwencje. Można kupić bardzo dobre UPS-y, zaprojektować rozdzielnice wysokiej jakości, dobrać agregaty z rezerwą mocy i nadal zbudować obiekt o niskiej dostępności. Wystarczy, że cała energia przechodzi przez jeden wspólny element, którego awaria albo serwis zatrzyma odbiory IT.
Z drugiej strony nie każdy obiekt potrzebuje Tier IV. Topologia musi wynikać z kosztu przerwy, wymagań biznesowych, organizacji utrzymania i ryzyka akceptowanego przez właściciela infrastruktury.
Tier I – podstawowa infrastruktura
Tier I oznacza podstawową infrastrukturę zasilania i chłodzenia. Obiekt ma jedną ścieżkę dystrybucji energii i nie ma komponentów nadmiarowych. Elementy infrastruktury takie jak UPS-y, rozdzielnice, systemy chłodzenia oraz ewentualne źródła rezerwowe pracują w układzie N.
Jeżeli trzeba wykonać przegląd, naprawę albo wymianę elementu w torze zasilania, odbiory IT zwykle trzeba wyłączyć. To samo dotyczy awarii pojedynczego elementu w podstawowej ścieżce zasilania.
Typowy układ od strony elektrycznej, jeżeli zastosowano zasilanie rezerwowe, można opisać tak:
sieć elektroenergetyczna, układ SZR, agregat, UPS, rozdzielnica zasilania gwarantowanego, odbiory IT.
Odbiory krytyczne, czyli przede wszystkim IT load i elementy bezpośrednio wymagające podtrzymania, są zasilane przez UPS. Pozostałe odbiory pomocnicze, np. część układów chłodzenia i wentylacji, mogą wrócić do pracy po uruchomieniu zespołu prądotwórczego, jeżeli taki układ rezerwowy został przewidziany. W tym poziomie nie ma redundancji N+1.
Historycznie z Tier I często łączy się orientacyjną dostępność 99,671%, co odpowiada około 28,8 h niedostępności rocznie. Nie jest to jednak gwarantowany wynik certyfikacji Uptime Institute. Klasa Tier opisuje przede wszystkim topologię infrastruktury i jej zachowanie podczas serwisu oraz awarii.
Tier I pasuje do małych serwerowni lub systemów, w których przerwa jest akceptowalna, a infrastruktura IT wspiera działalność, ale nie decyduje bezpośrednio o ciągłości usług w czasie rzeczywistym.
Tier II – redundantne komponenty, ale jedna ścieżka
Tier II dodaje komponenty nadmiarowe. Najczęściej oznacza to redundantne komponenty pojemnościowe (redundant capacity components), zwykle realizowane jako N+1 dla głównych systemów takich jak UPS, źródła rezerwowe lub chłodzenie.
Różnica względem Tier I jest znacząca, ale łatwo ją przecenić. W Tier II nadal mamy jedną podstawową ścieżkę dystrybucji zasilania. Redundantny może być komponent, ale niekoniecznie cała droga energii do odbioru końcowego.
Przykład: trzy moduły UPS pracują w układzie N+1. Awaria jednego modułu nie zatrzymuje odbiorów, bo pozostałe przejmują obciążenie. Ale jeżeli wszystkie moduły zasilają jedną wspólną szynę i jedną rozdzielnicę krytyczną, awaria tej szyny nadal może wyłączyć cały obiekt.
Planowany serwis elementu redundantnego nie musi powodować przerwy, ale dotyczy to tylko tych komponentów, które rzeczywiście mają redundancję. Serwis ścieżki dystrybucyjnej nadal może wymagać wyłączenia IT.
Historycznie z Tier II często łączy się orientacyjną dostępność 99,741%, czyli około 22 h niedostępności rocznie. W części źródeł wtórnych pojawia się 99,749%, ale w tym artykule przyjmuję jedną wartość referencyjną: 99,741%.
Tier II jest rozsądnym poziomem dla mniejszych obiektów, gdzie awaria jest kosztowna, ale krótkie okno serwisowe lub sporadyczna przerwa nie powoduje krytycznych konsekwencji biznesowych.
Tier III – utrzymanie bez wyłączenia IT
Tier III wprowadza pojęcie „concurrently maintainable”. Oznacza to możliwość prowadzenia planowanych prac utrzymaniowych bez wyłączenia odbiorów IT.
To jest punkt, w którym projektant elektryk powinien przestać liczyć tylko urządzenia i zacząć analizować ścieżki.
W Tier III każdy element infrastruktury wspierającej IT, który wymaga planowej obsługi serwisowej, powinien dać się odseparować, wyłączyć, serwisować albo wymienić bez utraty zasilania po stronie IT. Wymagane są redundantne komponenty oraz wiele niezależnych ścieżek dystrybucji, z których jedna musi obsługiwać IT w danym czasie. Nie wszystkie ścieżki muszą jednocześnie przenosić obciążenie, ale infrastruktura musi umożliwiać wyłączenie dowolnego elementu do serwisu bez zatrzymania IT.
Od strony zasilania trzeba sprawdzić nie tylko UPS-y i agregaty, ale też:
- rozdzielnice główne i sekcyjne,
- bypassy serwisowe,
- układy SZR, ATS i STS,
- PDU i RPP,
- trasy kablowe,
- pomieszczenia elektryczne,
- scenariusze przełączeń,
- zasilanie odbiorów dual-corded po stronie IT.
Najważniejsza różnica względem Tier II jest praktyczna. W Tier II część urządzeń można serwisować bez postoju, ale serwis ścieżki może zatrzymać odbiory. W Tier III planowany serwis elementów infrastruktury wspierającej IT nie powinien wyłączać IT.
Historycznie z Tier III często łączy się orientacyjną dostępność 99,982%, czyli około 1,6 h niedostępności rocznie. To wartość referencyjna, a nie gwarancja uzyskiwana samą certyfikacją topologii.
Tier III pasuje do obiektów, które muszą pracować 24/7, ale dopuszczają krótkie przerwy wynikające z określonych zdarzeń awaryjnych. W praktyce to częsty poziom dla komercyjnych data center i infrastruktury biznesowo krytycznej.
Tier IV – odporność na pojedynczą awarię
Tier IV idzie dalej niż Tier III. Obiekt ma nie tylko pozwalać na serwis bez wyłączenia IT, ale także przetrwać pojedynczą awarię elementu lub ścieżki bez wpływu na odbiory końcowe.
To jest różnica między „mogę planowo wyłączyć element” a „element może uszkodzić się sam i system nadal pracuje”.
Od strony elektrycznej Tier IV najczęściej realizuje się przez dwa niezależne, fizycznie odseparowane systemy A/B, np. 2N lub 2(N+1). Kluczowym wymaganiem jest jednak odporność topologii na pojedynczą awarię, a nie sama nazwa konfiguracji. Architektura musi zapewnić możliwość utrzymania obciążenia krytycznego po wystąpieniu pojedynczej awarii, bez wpływu na odbiory IT.
Separacja dotyczy nie tylko rozdzielnic i UPS-ów. Dotyczy także tras kablowych, pomieszczeń, systemów chłodzenia, automatyki, wejść kablowych, zabezpieczeń pożarowych i organizacji utrzymania. W Tier IV wspólny punkt między torem A i B trzeba traktować jako potencjalny single point of failure.
Historycznie z Tier IV często łączy się orientacyjną dostępność 99,995%, czyli około 26,3 min niedostępności rocznie. To nadal wartość referencyjna, nie gwarantowany parametr SLA wynikający z samego poziomu Tier.
Tier IV jest uzasadniony tam, gdzie brak dostępu do infrastruktury oznacza bardzo duże straty finansowe, konsekwencje prawne albo ryzyko strategiczne. Przykładami są systemy bankowe, operatorzy płatności, giełdy, infrastruktura globalna i wybrane obiekty hyperscale.
Porównanie poziomów Tier
| Parametr | Tier I | Tier II | Tier III | Tier IV |
|---|---|---|---|---|
| Podstawowa idea | infrastruktura podstawowa | redundantne komponenty | serwis bez wyłączenia IT | odporność na pojedynczą awarię |
| Redundancja | N | redundantne komponenty pojemnościowe, zwykle N+1 | redundantne komponenty + wiele ścieżek dystrybucji | najczęściej 2N lub 2(N+1) |
| Ścieżki dystrybucji | jedna | jedna | co najmniej dwie | co najmniej dwie, fizycznie odseparowane |
| Planowany serwis bez postoju IT | nie | częściowo | tak | tak |
| Odporność na pojedynczą awarię | brak | ograniczona | niepełna | tak |
| Historycznie cytowana dostępność | 99,671% | 99,741% | 99,982% | 99,995% |
| Historycznie cytowany przestój roczny | 28,8 h | około 22 h | około 1,6 h | około 26,3 min |
Wartości dostępności i przestojów w tabeli traktuję jako klasyczne wartości referencyjne powtarzane w materiałach branżowych. Nie są one gwarantowanym wynikiem certyfikacji Uptime Institute. Przed użyciem w dokumentacji projektowej trzeba potwierdzić je w źródle przyjętym przez inwestora.
Dlaczego Tier III często jest wyborem optymalnym
Tier IV daje najwyższą historycznie cytowaną dostępność, ale kosztuje znacznie więcej. Wymaga odpornej topologii, separacji fizycznej, większej powierzchni, większej liczby rozdzielnic, większej liczby tras, bardziej rozbudowanej automatyki i bardziej rygorystycznego utrzymania.
Różnica między Tier III i Tier IV w dostępności liczbowej jest mniejsza niż różnica w kosztach budowy i utrzymania. Dlatego w wielu przypadkach Tier III jest bardziej racjonalnym wyborem: daje możliwość serwisu bez postoju, ogranicza ryzyko planowanych przerw i nie wymaga pełnej architektury fault tolerant.
To nie oznacza, że Tier IV jest „przesadą”. Oznacza tylko, że trzeba policzyć koszt przerwy. Jeżeli godzina niedostępności kosztuje więcej niż różnica między topologią Tier III i Tier IV w całym cyklu życia obiektu, wybór Tier IV zaczyna mieć uzasadnienie.
EN 50600 a klasy Tier
W Europie przy projektowaniu data center często pojawia się również norma EN 50600. Nie jest to proste tłumaczenie klasyfikacji Tier.
EN 50600 patrzy na obiekt szerzej i pozwala klasyfikować różne obszary infrastruktury oddzielnie, m.in. zasilanie, chłodzenie, okablowanie, bezpieczeństwo fizyczne i organizację eksploatacji. Stosuje się tu klasy dostępności (Availability Classes, AC1-AC4), które nie są bezpośrednimi odpowiednikami Tier I-IV. W praktyce oznacza to, że obiekt może mieć wysoką klasę dostępności dla zasilania, ale niższą dla innego obszaru.
Orientacyjnie można zestawiać Tier I z AC1, Tier II z AC2, Tier III z AC3, a Tier IV z AC4, ale nie jest to równoważność 1:1 i nie powinno być używane jako deklaracja zgodności. EN 50600 klasyfikuje obszary infrastruktury bardziej modułowo niż klasyfikacja Tier. [3][4]
Dla projektanta elektryka wniosek jest prosty: sam dobry układ UPS nie wystarczy, jeżeli chłodzenie, trasy kablowe, procedury serwisowe albo automatyka pozostają na niższym poziomie.
Tier III+, Tier 3.5 i inne etykiety marketingowe
W materiałach sprzedażowych można spotkać określenia typu „Tier III+”, „Tier 3.5” albo „prawie Tier IV”. Z punktu widzenia klasyfikacji Uptime Institute nie są to formalne poziomy certyfikacji.
Obiekt jest zgodny z konkretnym poziomem Tier albo nie jest. Jeżeli topologia spełnia wymagania Tier III, ale nie spełnia wymagań odporności na pojedynczą awarię dla Tier IV, to technicznie pozostaje Tier III. Dodatkowe określenia mogą być użyteczne marketingowo, ale nie zastępują analizy topologii.
Błąd 1 – wspólna szyna wyjściowa UPS
Najprostszy sposób na zniszczenie redundancji to wspólna szyna za dwoma systemami UPS.
Na schemacie widzimy UPS A i UPS B. Oba mają swoje wejścia, baterie i falowniki. Wygląda jak układ 2N. Potem ich wyjścia trafiają na jedną wspólną szynę albo jeden wspólny wyłącznik główny przed dystrybucją do PDU.
W tym momencie wspólna szyna staje się single point of failure. Awaria szyny, zwarcie, błąd łączeniowy albo zadziałanie wspólnego wyłącznika może wyłączyć oba tory jednocześnie.
W układzie A/B trzeba unikać wspólnych elementów między wyjściem UPS a odbiorami końcowymi. Dotyczy to również wspólnych baterii, wspólnych szyn DC i wspólnych bypassów.
Wyjątkiem mogą być elementy zaprojektowane jako część kontrolowanej architektury przełączeniowej, które same spełniają wymagania dostępności i utrzymania dla zakładanego poziomu.
Błąd 2 – wspólna rozdzielnica generatorów
Redundancja generatorów N+1 poprawia odporność na awarię pojedynczego agregatu. Nie rozwiązuje jednak problemu wspólnej szyny w rozdzielnicy paralleling switchgear.
Problemem nie jest samo równoleglenie generatorów, ale taki układ rozdzielnicy, w którym pojedyncza awaria wspólnego elementu powoduje utratę całej funkcji zasilania rezerwowego. Jeżeli wszystkie agregaty synchronizują się na jednej, niepodzielonej szynie, to awaria tej szyny może wyłączyć całe źródło rezerwowe. Liczba agregatów nie pomaga, jeśli cała ich energia przechodzi przez jeden wspólny punkt.
Bardziej zaawansowane układy mogą stosować podzielone szyny, łączniki sekcyjne, izolację sekcji albo redundantny switchgear. Sama obecność paralleling switchgear nie przekreśla topologii, ale jego projekt musi eliminować pojedyncze zdarzenie wyłączające całą funkcję rezerwową.
Dla architektury zbliżonej do Tier IV bardziej naturalne są dwa odseparowane układy generatorowe dla toru A i toru B. Każdy tor powinien mieć własną dystrybucję i własne elementy krytyczne.
Błąd 3 – jeden ATS dla zbyt dużego fragmentu obiektu
Jeden przełącznik ATS bez bypassu serwisowego może stać się wąskim gardłem całej instalacji.
Jeżeli przez jeden ATS przechodzi zasilanie dużej części infrastruktury krytycznej, jego awaria albo planowany serwis może wymagać postoju. W teorii obiekt ma źródło podstawowe i rezerwowe. W praktyce ma jeden element, którego nie da się obsłużyć bez ryzyka dla odbiorów.
W obiektach o wyższej dostępności trzeba analizować nie tylko funkcję automatycznego przełączenia, ale też możliwość utrzymania samego przełącznika. Bypass serwisowy, podział na sekcje i rozdzielenie funkcji przełączania ograniczają ryzyko.
Błąd 4 – wspólne trasy kablowe A i B
Dwa tory A i B nie są niezależne, jeżeli idą tą samą drabinką kablową, tym samym kanałem albo przez ten sam przepust.
Pożar, zalanie, uszkodzenie mechaniczne, prace remontowe albo błąd wykonawcy mogą uszkodzić oba tory jednym zdarzeniem. Na schemacie mamy A/B. W budynku mamy jeden wspólny punkt awarii.
Separacja fizyczna jest jednym z najczęściej niedocenianych elementów. Obejmuje nie tylko trasy kablowe, ale też pomieszczenia, wejścia kablowe, szachty, przejścia przez przegrody i strefy pożarowe.
Błąd 5 – odbiory single-corded w układzie 2N
Obiekt może mieć dwa niezależne tory zasilania, ale jeżeli odbiornik końcowy ma tylko jeden zasilacz i jeden przewód, dla tego odbiornika realnego A/B nie ma.
Serwery, urządzenia sieciowe lub systemy pomocnicze single-corded wymagają dodatkowego rozwiązania po stronie szafy, np. STS, albo świadomej akceptacji ryzyka. Bez tego odbiornik końcowy staje się najsłabszym punktem całej topologii.
To dotyczy również urządzeń pomocniczych, które często są pomijane w analizie: sterowników, przełączników sieciowych automatyki, systemów monitoringu, paneli operatorskich, urządzeń komunikacyjnych i zasilaczy pomocniczych.
Błąd 6 – automatyka bez testów całego scenariusza
Redundancja sprzętowa nie wystarczy, jeżeli logika przełączeń nie została sprawdzona pod obciążeniem.
BAS, EPMS, SZR, ATS, STS, sterowanie generatorów, sygnały gotowości, blokady i alarmy muszą być testowane jako jeden system. Jeżeli projekt robi kilka branż bez wspólnego scenariusza testów, układ może wyglądać poprawnie na schemacie i zawieść podczas rzeczywistego zdarzenia.
Przykład: generator uruchamia się poprawnie, ale sygnał gotowości dociera z opóźnieniem. UPS-y pracują na bateriach dłużej niż zakładano. Chłodzenie wraca z opóźnieniem. Obiekt formalnie ma redundancję, ale nie ma potwierdzonego zachowania w czasie awarii.
Błąd 7 – brak selektywności i marginesów po rozbudowie
Data center rzadko pozostaje w stanie z dnia odbioru. Dochodzą nowe szafy, nowe PDU, większa gęstość mocy, dodatkowe systemy chłodzenia i zmiany po stronie IT.
Jeżeli rozbudowa nie jest prowadzona razem z analizą obciążeń, selektywności i nastaw zabezpieczeń, układ może utracić pierwotny poziom odporności. Wyłącznik dobrany poprawnie dla pierwszego etapu może stać się zbyt mały po kilku latach rozbudowy.
W układach zasilania gwarantowanego trzeba regularnie porównywać rzeczywiste obciążenie z założeniami projektu. Dotyczy to prądów roboczych, prądów zwarciowych, nastaw zabezpieczeń, obciążenia neutralnego, mocy generatorów i zdolności UPS do pracy w aktualnym profilu obciążenia.
Jak analizować topologię zasilania data center
Najprostsza metoda analizy to przejście od źródła do odbioru i zaznaczenie miejsc wspólnych.
- Gdzie są punkty wejścia zasilania zewnętrznego?
- Czy źródła rezerwowe mają wspólne elementy dystrybucji?
- Czy UPS A i UPS B mają wspólną szynę, bypass, baterię albo sterowanie?
- Czy rozdzielnice A i B są fizycznie odseparowane?
- Czy trasy kablowe A i B idą różnymi drogami?
- Czy odbiory IT są dual-corded?
- Czy urządzenia single-corded mają STS albo akceptację ryzyka?
- Czy każdy element można wyłączyć do serwisu bez utraty obciążenia?
- Czy pojedyncza awaria urządzenia lub ścieżki wyłącza odbiory?
- Czy scenariusze przełączeń były testowane pod obciążeniem?
Jeżeli odpowiedź na jedno z tych pytań jest niejasna, deklarowany Tier wymaga weryfikacji.
Co wynika z klasyfikacji Tier dla projektanta elektryka
Tier I i Tier II są tańsze, ale awaria albo przegląd techniczny może oznaczać przerwę w zasilaniu odbiorów końcowych. Jeżeli koszt takiej przerwy jest mały, nie ma sensu budować infrastruktury jak dla giełdy albo operatora płatności.
Jeżeli koszt przerwy jest wysoki, trzeba analizować Tier III i Tier IV. Tier III daje możliwość planowanego utrzymania bez zatrzymania IT. Tier IV dodaje odporność na pojedynczą awarię, ale wymaga pełniejszej separacji i znacznie większej dyscypliny projektowej.
Najgorszy wariant to obiekt z drogimi urządzeniami i topologią, która nadal ma jeden wspólny punkt awarii. Wtedy inwestor płaci za sprzęt, ale nie otrzymuje oczekiwanej dostępności.
Wniosek praktyczny
Przy analizie zasilania data center nie zaczynałbym od pytania, ile UPS-ów jest w projekcie.
Zacząłbym od trzech pytań:
- Co można wyłączyć do serwisu bez utraty IT?
- Co może się uszkodzić bez utraty IT?
- Gdzie tor A i tor B spotykają się w jednym miejscu?
Tier III odpowiada przede wszystkim na pierwsze pytanie. Tier IV dodaje odpowiedź na drugie. Trzecie pytanie jest praktycznym testem całej topologii.
Jeżeli tory A i B spotykają się na wspólnej szynie, wspólnej rozdzielnicy, wspólnym ATS, wspólnym bypassie, wspólnej trasie kablowej albo pojedynczym odbiorniku, to właśnie tam zaczyna się ryzyko, którego nie widać po samej liczbie UPS-ów.
Projektowanie układów zasilania gwarantowanego, analiza topologii UPS, współpraca z agregatami, dobór bypassów, selektywność i typowe błędy w architekturze A/B będą częścią kursu Układy Napięcia Gwarantowanego.
Bibliografia
[1] Uptime Institute, Tier Standard: Topology, najnowsze dostępne wydanie.
[2] ANSI/TIA-942, Telecommunications Infrastructure Standard for Data Centers, aktualne wydanie; historycznie: ANSI/TIA-942-B, Telecommunications Industry Association, lipiec 2017.
[3] EN 50600-1, Information technology – Data centre facilities and infrastructures – General concepts.
[4] EN 50600-2-2:2019, Information technology – Data centre facilities and infrastructures – Part 2-2: Power supply and distribution.